Background Information
This project aims to help investors learn more about a random city in order to determine optimal locations for business investments. The data used in this project was obtained using Foursquare's developer API.
Fields include:
- Venue Name
- Venue Category
- Venue Latitude
- Venue Longitude
There are 232 records found using the center of Lincoln as the area of interest with a radius of 10,000.
Import the Data
The first step is the simplest: import the applicable libraries. We will be using the libraries below for this project.
# Import the Python libraries we will be using
To begin our analysis, we need to import the data for this project. The data we are using in this project comes directly from the Foursquare API. The first step is to get the latitude and longitude of the city being studied (Lincoln, NE) and setting up the folium map.
# Define the latitude and longitude, then map the results
= 40.806862
= -96.681679
=
Now that we have defined our city and created the map, we need to go get the business data. The Foursquare API will limit the results to 100 per API call, so we use our first API call below to determine the total results that Foursquare has found. Since the total results are 232, we perform the API fetching process three times (100 + 100 + 32 = 232).
# Foursquare API credentials
=
=
=
# Set up the URL to fetch the first 100 results
= 100
= 10000
=
# Fetch the first 100 results
=
# Determine the total number of results needed to fetch
=
# Set up the URL to fetch the second 100 results (101-200)
= 100
= 100
= 10000
=
# Fetch the second 100 results (101-200)
=
# Set up the URL to fetch the final results (201 - 232)
= 100
= 200
= 10000
=
# Fetch the final results (201 - 232)
=
Clean the Data
Now that we have our data in three separate dataframes, we need to combine them
into a single dataframe and make sure to reset the index so that we have a
unique ID for each business. The get~categorytype~ function below will pull
the categories and name from each business's entry in the Foursquare data
automatically. Once all the data has been labeled and combined, the results are
stored in the nearby_venues dataframe.
# This function will extract the category of the venue from the API dictionary
=
=
return None
return
# Get the first 100 venues
=
=
# filter columns
=
=
# filter the category for each row
=
# clean columns
=
---
# Get the second 100 venues
=
= # flatten JSON
# filter columns
=
=
# filter the category for each row
=
# clean columns
=
=
---
# Get the rest of the venues
=
= # flatten JSON
# filter columns
=
=
# filter the category for each row
=
# clean columns
=
=
=
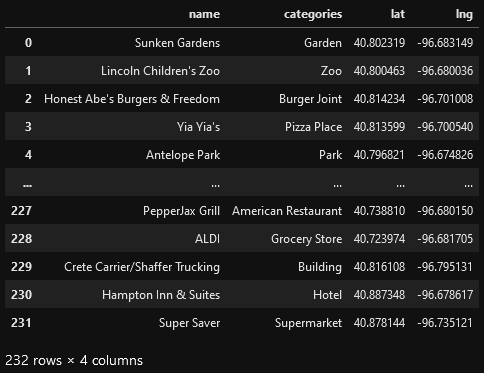
Visualize the Data
We now have a complete, clean data set. The next step is to visualize this data
onto the map we created earlier. We will be using folium's CircleMarker()
function to do this.
# add markers to map
=
=
Clustering: k-means
To cluster the data, we will be using the k-means algorithm. This algorithm is iterative and will automatically make sure that data points in each cluster are as close as possible to each other, while being as far as possible away from other clusters.
However, we first have to figure out how many clusters to use (defined as the variable 'k'). To do so, we will use the next two functions to calculate the sum of squares within clusters and then return the optimal number of clusters.
# This function will return the sum of squares found in the data
=
=
return
# Drop 'str' cols so we can use k-means clustering
=
# calculating the within clusters sum-of-squares for 19 cluster amounts
=
# This function will return the optimal number of clusters
, = 2,
, = 20,
=
= +2
=
=
=
return + 2
# calculating the optimal number of clusters
=
Now that we have found that our optimal number of clusters is six, we need to perform k-means clustering. When this clustering occurs, each business is assigned a cluster number from 0 to 5 in the dataframe.
# set number of clusters equal to the optimal number
=
# run k-means clustering
=
# add clustering labels to dataframe
Success! We now have a dataframe with clean business data, along with a cluster number for each business. Now let's map the data using six different colors.
# create map with clusters
=
=
# add markers to the map
=
=
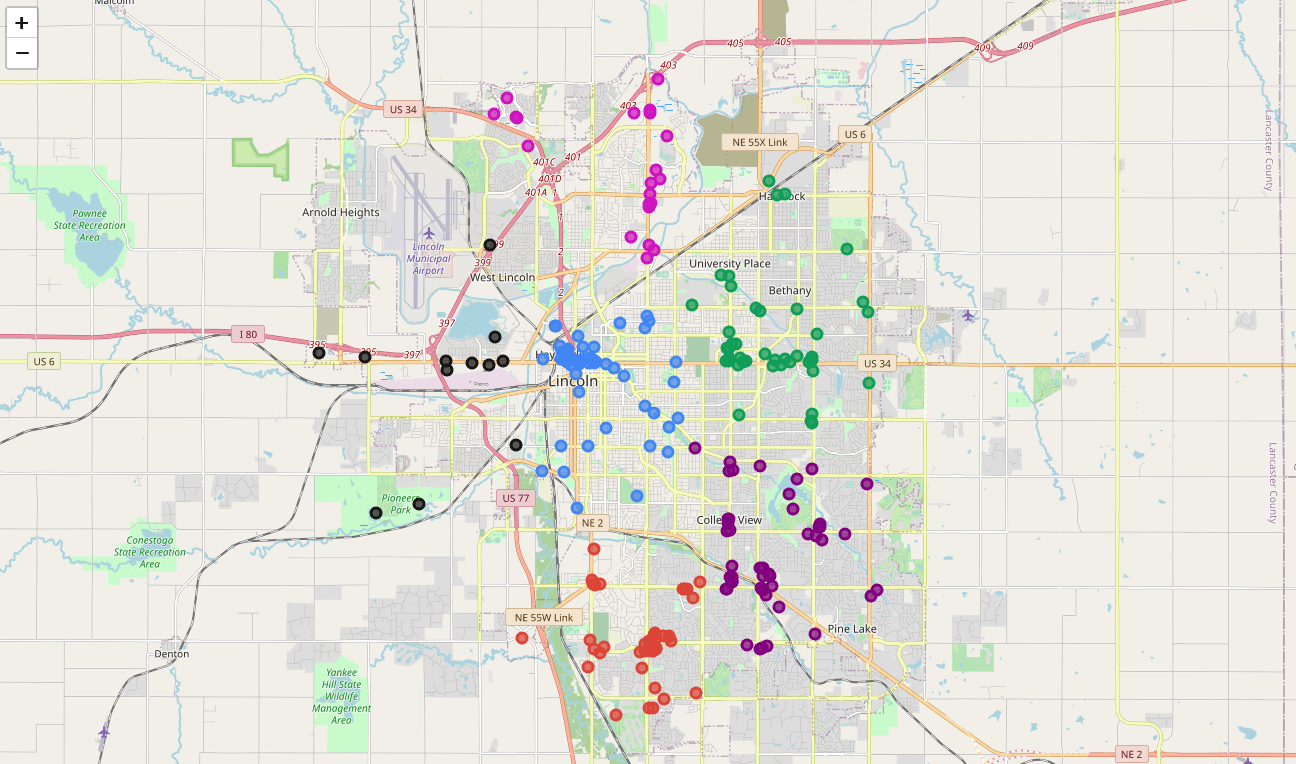
Investigate Clusters
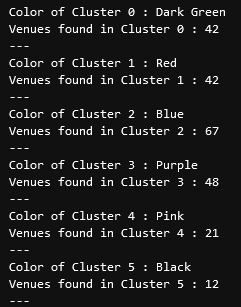
Now that we have figured out our clusters, let's do a little more analysis to provide more insight into the clusters. With the information below, we can see which clusters are more popular for businesses and which are less popular. The results below show us that clusters 0 through 3 are popular, while clusters 4 and 5 are not very popular at all.
# Show how many venues are in each cluster
=
Our last piece of analysis is to summarize the categories of businesses within each cluster. With these results, we can clearly see that restaurants, coffee shops, and grocery stores are the most popular.
# Calculate how many venues there are in each category
# Sort from largest to smallest
=
=
=
=
=
=
=
# show how many venues there are in each cluster (> 1)
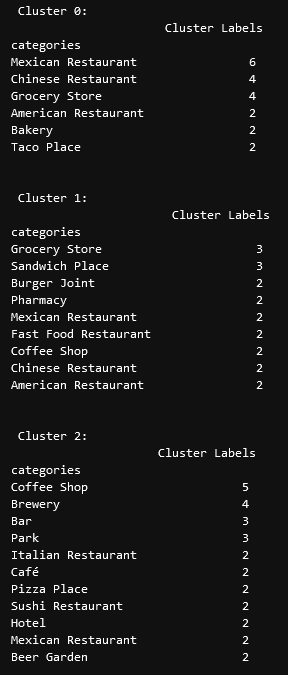
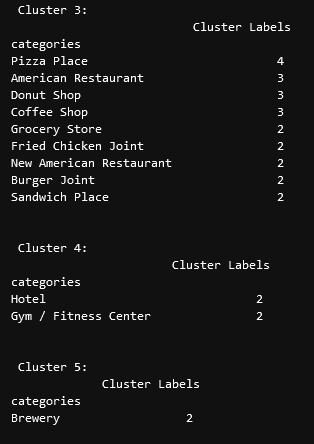
Discussion
In this project, we gathered location data for Lincoln, Nebraska, USA and clustered the data using the k-means algorithm in order to identify the unique clusters of businesses in Lincoln. Through these actions, we found that there are six unique business clusters in Lincoln and that two of the clusters are likely unsuitable for investors. The remaining four clusters have a variety of businesses, but are largely dominated by restaurants and grocery stores.
Using this project, investors can now make more informed decisions when deciding the location and category of business in which to invest.
Further studies may involve other attributes for business locations, such as population density, average wealth across the city, or crime rates. In addition, further studies may include additional location data and businesses by utilizing multiple sources, such as Google Maps and OpenStreetMap.